The project will be carried out in a traditional, sequential methodology on its highest level. The project plan will be split into 4 major stages succeeding one after another without any reiteration, which will allow us to better evaluate the degree of meeting the project goals and deadlines at any time. The following text describes methodologies of each of the major process stages.
Phase 1 – Data Collection
A biography incorporates a huge bundle of facts and a complex series of events comprising the life of a person. Biographical facts may be classified on two levels according to a hierarchy of relevance, described in details in Sergio Soares’s dissertation on “Extraction of Biographical Information from Wikipedia Texts”. Soares distinguishes immutable personal characteristics (e.g. date and place of birth/death, family information), mutable personal characteristics (education, occupation, residence, affiliation), relational personal characteristics (family and marital relationships, professional collaborations), individual events (professional activities, personal events) and others among biographical data, while excluding irrelevant (non-biographical) details on a zero level.
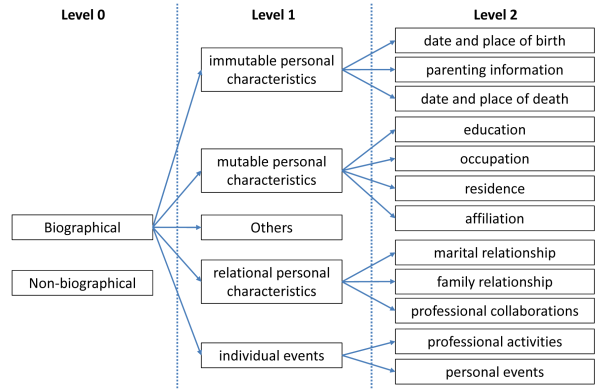
During the Data Collection phase we will collect Nietzsche’s biographical data and store them in a structured database (a relational database management system). The phase may be divided to three distinct subphases: data source aggregation, data model design (incorporating the taxonomy of biographical classes, proposed by Soares) for storing and accessing them logically and efficiently and database population.
The data source aggregation subphase will consist of identifying various reliable data sources, selecting the relevant data to be stored, verifying and merging them with the data present in the database. The types of sources we are going to use are the following (sorted in descending order of priority):
- Web content created by acclaimed universities
- Web content created by reliable encyclopedias (e.g. Britannica)
- Printed biographies written by established authors
- Web content created by other reputable institutions
- Other sources
To store, analyze, process and update the data in the RDBMS quickly and correctly, an appropriate data model has to be designed. A data model defines the types and relationships of data to be stored and is the basis for any further work. Our goal will be to decompose the collected data into as small pieces of information as possible, in order to leverage the advantages of a structured database the most. During the data collection we will find various types of data and it will happen incrementally, hence the data model must also change in time accordingly.
Furthermore, additional entities and relations, which will represent the taxonomy of the biographical classses, will be created. They will facilitate the classification of biographical facts and provide information about their origin.
The process of data extraction and database population is described as follows:
- Assemble a list of online resources identified by unique URLs
- Create a local repository of the digitized texts to be mined
- Download a recent version of the specified web pages and save the HTML content in the repository by using a website crawler
- Add biographical data from digitized books in plain text format to the repository manually
- Parse the repository data, scrape names of people and places, and store them in an entity table
- Build Wikipedia resource locators from the named entities, fetch and extract infobox information and save it to the database
- Strip HTML tags and irrelevant data
- Delimit individual tokens over the text, segment the documents into sentences and classify them into the biographical classes, discussed above, manually or with the assistance of appropriate data mining software
- Import images and multimedia, related to Nietzsche
Phase 2 – Data Analysis
After we create a large enough structured database with Nietzsche’s biographical data, we will try to analyse it by using text mining tools, compile descriptive statistics and draw conclusions on it. The following domains of Nietzsche’s biography will be explored:
- Circles of friends and acquaintances
- Public events and social interactions
- Journeys and places of residence
- Literary work
- Aspirations and external drivers
All statistics will be based on the data stored in the biographical database and the applications that will produce them (and eventually visualize them in graphs, diagrams, maps, etc.) will be reusable on the website that we will create in the following phase. The compiled statistical data will be preserved in database tables or made accessible via database views.
Phase 3 – Website Development
In the third phase of our project we will design and develop a dedicated website where a subset of the collected data about Nietzsche and all the derived statistics will be published. The content will be presented very cleanly, but attractively and, if possible, graphically.
The website will be highly interactive (via the use of AJAX, partial rendering and dynamic filters). Events plotted on a timeline, spatial distribution of people and places, a network of Nietzsche’s friends and acquaintances are exemplary applications suited for the interative presentation of the data.
Moreover, the website will be very well interlinked and contextual so that the reader will never have hard time finding needed or related information.
Phase 4 – Results Summarization
In the last phase of the project we are going to summarize the results in a final document, which will also be published in a section of the project website.
